





List of libraries required to be installed (if not already installed). Here installation is done through Jupyter Notebook. For terminal use only "pip install library-name".
#import sys
#!{sys.executable} -m pip install numpy
#!{sys.executable} -m pip install pandas
#!{sys.executable} -m pip install sklearn
#!{sys.executable} -m pip install hvplot
#!{sys.executable} -m pip install six
#!{sys.executable} -m pip install pydotplus
#!{sys.executable} -m pip install python-graphviz
Importing libraries:
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import hvplot.pandas
About the dataset
Imagine that you are a medical researcher compiling data for a study. You have collected data about a set of patients, all of whom suffered from the same illness. During their course of treatment, each patient responded to one of 5 medications, Drug A, Drug B, Drug c, Drug x and y.
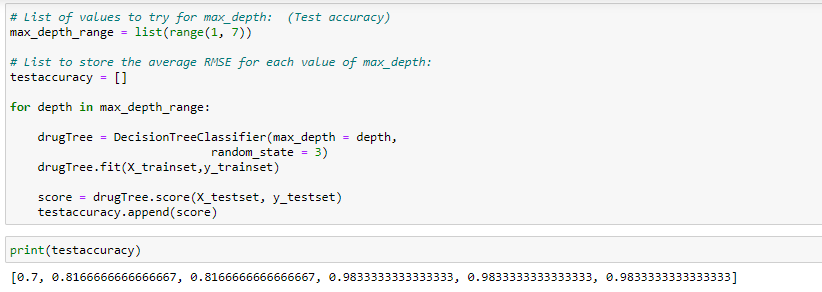
Part of your job is to build a model to find out which drug might be appropriate for a future patient with the same illness. The feature sets of this dataset are Age, Sex, Blood Pressure, and Cholesterol of patients, and the target is the drug that each patient responded to.
It is a sample of binary classifier, and you can use the training part of the dataset to build a decision tree, and then use it to predict the class of a unknown patient, or to prescribe it to a new patient.
Let's see the sample of dataset:






















0 comments:
Post a Comment