





Introduction
This project visualizes the Covid-19 data (i.e. Total cases, Deaths and Recoveries) across various Provinces and Districts of Nepal as of 9th August, 2020. Geojson file of Nepal's states and districts have been used. Also python library i.e. Folium has been used to generate Choropleth map whose geo_data value is the geojson of Nepal.
The libraries imported are:

Data description:
Covid-19 data of various provinces and districts were scrapped from wikipedia.
Click here to go to the wikipedia page.
Simple one line code can be used to scrap the table of wikipedia. We will store the scrapped data into a dataframe called 'df'.
df = pd.read_html('https://en.wikipedia.org/wiki/Template:COVID-19_pandemic_data/Nepal_medical_cases_by_province_and_district')[1]
Original view of data:

Data Wrangling/ Cleaning:
Step 1:
We can see in data above that the columns are of multi-index. So, converting it into single index columns.

Step 2:
Dropping the 'Index Case column'.
df.drop(columns=['Index Case'], axis=1, inplace=True)
Step 3:

We can see the rows with index 84 (it's a grand total case in Nepal) and 85 are not required so dropping them out.
df=df[:-2] # Getting all rows except the last two rows
Step 4:

We can see in above image that the data types of columns Cases, Recovered and Deaths are not in desired form. So, converting them into 'integer'.

Step 5:
Our dataframe (df) after cleaning looks like this:

We can see the data of Provinces and Districts are together in single dataframe. So, we need to separate them into different dataframes.
Creating a dataframe of Provinces only:
Step 1:
Extracting the data of only provinces into a new dataframe called df_prov.
We can use two methods to do so.
Method 1
#df_prov=df.iloc[[0, 15, 24, 38, 50, 63, 74],:]
Method 2 (More robust method as in above method the index of provinces may change in original link of data)
df_prov=df[df['Location'].str.contains('Province') | df['Location'].str.contains('Bagmati') | df['Location'].str.contains('Gandaki') | df['Location'].str.contains('Karnali') | df['Location'].str.contains('Sudurpashchim') ]



Visualizing the data of provinces:


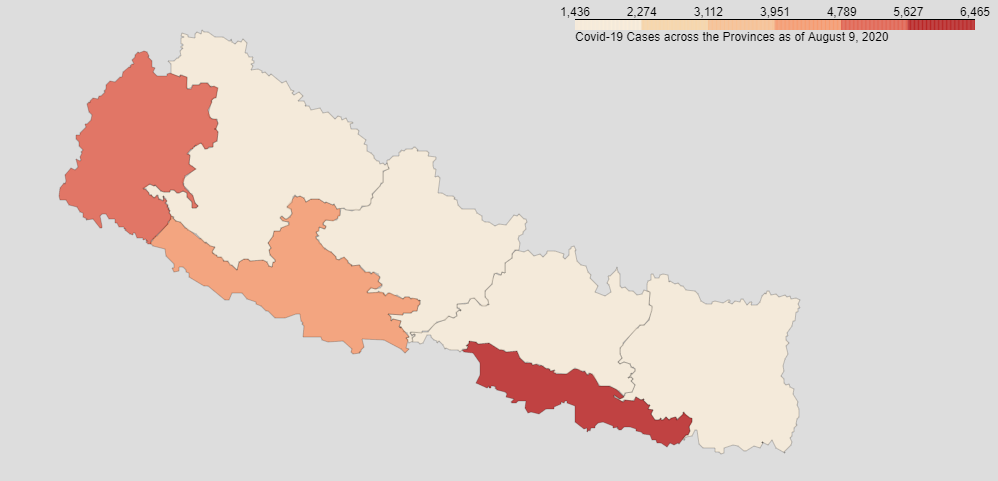


Creating a dataframe of districts only:

Visualizing data of districts:


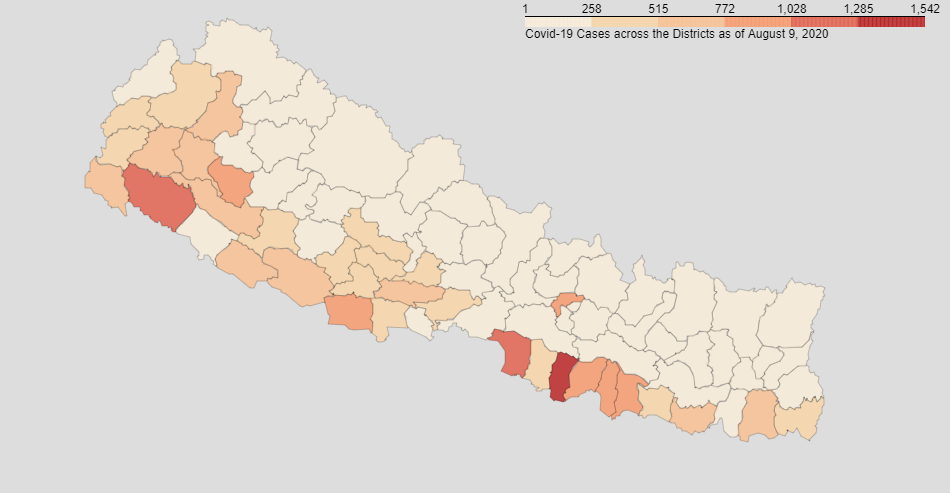

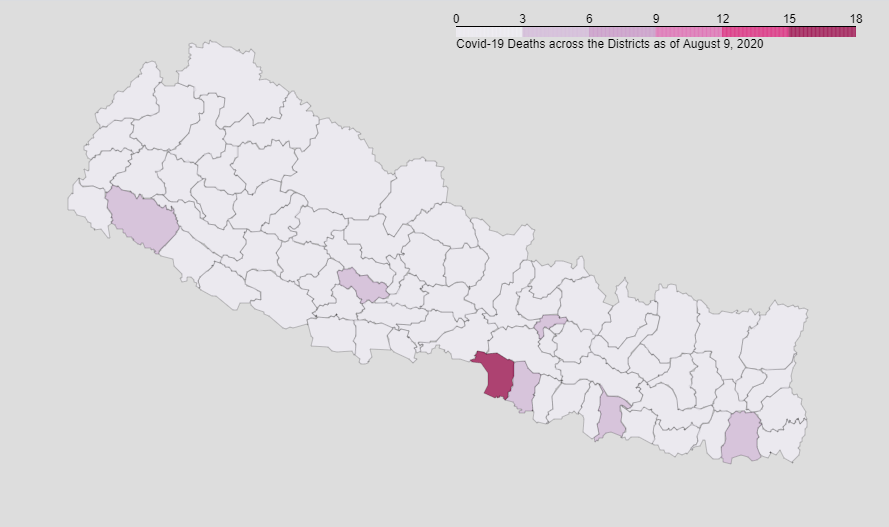




0 comments:
Post a Comment