





In traditional neural networks, inputs and outputs were independent of each other. To predict next word in a sentence, it is difficult for such model to give correct output, as previous words are required to be remembered to predict the next word. For example, to predict the ending of a movie, it depends on how much one has already watched the movie and what contexts have arrived to that point of time in the movie. In the same way, RNN remembers everything. It overcomes the shortcomings of traditional neural network with the help of hidden layers. Because of the quality to remember the previous inputs, it useful in prediction of time series. This is called Long Short-Term Memory (LSTM).

Fig: LSTM Architecture
Combining two independent RNN together forms a Bi-LSTM (Bidirectional Long Short-Term Memory). It allows the network to have both forward and backward information. Bi-LSTM gives better result as it takes the context into consideration.
Example:

In NLP, to find the next word, it is not that we need only the previous word but also the upcoming word. As shown in the example above, to predict what comes after the word “Teddy”, we can’t be dependent only upon the previous word (which is “said” in this case) because it same in both the cases. Here, we need to consider the context as well. If we predict “Roosevelt” in the first case then it will be out of context as it will read as [He said, “Teddy Roosevelt are on sale!”]. So, Bi-LSTM is important to taken context into consideration.
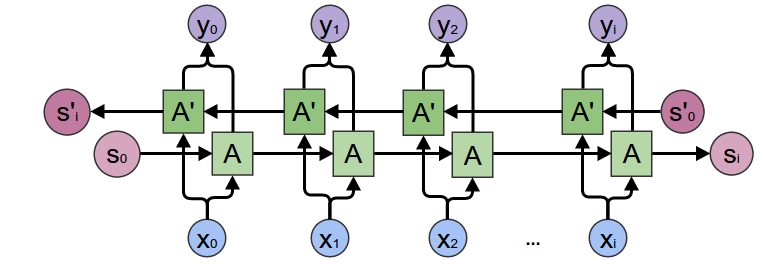
Fig: Bi-LSTM Architecture




0 comments:
Post a Comment