





It is difficult to perform analysis on the text so we use word embedding techniques to convert the texts into numerical representation. This is also called vectorization of the words. It is a representation technique for text in which words having same meaning are given similar representation. It helps to extract features from the text.
i. Bag of Words (BoW)
It is one of the most widely used technique for word embedding. This method focuses on the frequency of the words. It is easy to implement and also efficient at the same time. In Python, we can use CountVectorizer() function from sklearn library to implement Bag of Words. A graphical representation of bag of Words has been shown in the figure below.
The reason for selecting BoW as word embedding technique is that it is still widely used technique due to its simplicity in implementation. It is also very useful when working on a domain specific dataset. If not entirely, it does give some idea to the researchers regarding the performance of the work.

Fig: Representation of BoW
ii. TF-IDF (Term Frequency- Inverse Document Frequency)
Term Frequency is used to count the number of words in a document. It is not necessary that the words with higher frequencies tend to represent significant information about the document. A word appearing in a document for many times does not mean it is relevant and significant all the time. Many times, words with less frequencies carry more significant meanings about the document. One way to normalize the frequency of words is to use TF-IDF. Inverse Document Frequency (IDF) is used to calculate the significance of rare words or words with less frequencies.


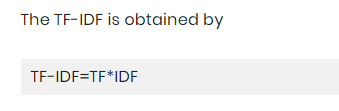
The reason for using TF-IDF is it can be used to find and remove stop words in the textual data. It helps to find unique identifier in a text. It helps to understand the importance of a words in entire document which in turn can help in text summarization.




0 comments:
Post a Comment