






AITB International Conference, 2019
Kathmandu, Nepal

My Youtube Channel
Please Subscribe

Flag of Nepal
Built in OpenGL

World Covid-19 Data Visualization
Choropleth map

Word Cloud in Python
With masked image
Saturday, June 26, 2021
Friday, June 25, 2021
Saturday, June 19, 2021
Wednesday, June 9, 2021
Sunday, June 6, 2021
Saturday, June 5, 2021
Friday, June 4, 2021
Wednesday, June 2, 2021
Saturday, November 28, 2020
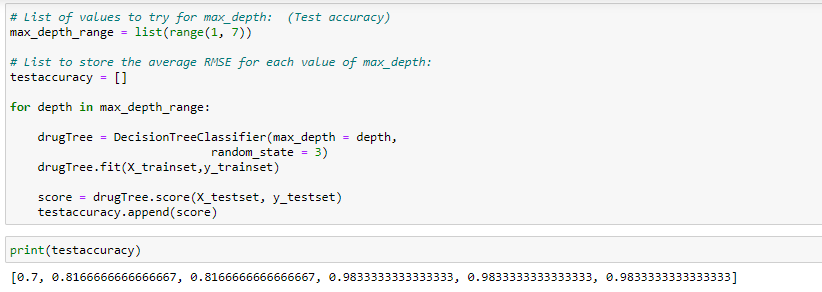
Visualizing Decision tree in Python (with codes included)
List of libraries required to be installed (if not already installed). Here installation is done through Jupyter Notebook. For terminal use only "pip install library-name".
#import sys
#!{sys.executable} -m pip install numpy
#!{sys.executable} -m pip install pandas
#!{sys.executable} -m pip install sklearn
#!{sys.executable} -m pip install hvplot
#!{sys.executable} -m pip install six
#!{sys.executable} -m pip install pydotplus
#!{sys.executable} -m pip install python-graphviz
Importing libraries:
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import hvplot.pandas
About the dataset
Imagine that you are a medical researcher compiling data for a study. You have collected data about a set of patients, all of whom suffered from the same illness. During their course of treatment, each patient responded to one of 5 medications, Drug A, Drug B, Drug c, Drug x and y.
Part of your job is to build a model to find out which drug might be appropriate for a future patient with the same illness. The feature sets of this dataset are Age, Sex, Blood Pressure, and Cholesterol of patients, and the target is the drug that each patient responded to.
It is a sample of binary classifier, and you can use the training part of the dataset to build a decision tree, and then use it to predict the class of a unknown patient, or to prescribe it to a new patient.
Let's see the sample of dataset:


















Tuesday, November 10, 2020
Python code to extract Temporal Expression from a text (Using Regular Expression)
#Method 1
Code:
import re
print('Enter the text:')
text = input()
months='(Jan(?:uary)?|Feb(?:ruary)?|Mar(?:ch)?|Apr(?:il)?|May|Jun(?:e)?|Jul(?:y)?|Aug(?:ust)?|Sep(?:tember)?|Oct(?:ober)?|(Nov|Dec)(?:ember)?)'
re1=r'\w?((mor|eve)(?:ning)|after(?:noon)?|(mid)?night|today|tomorrow|(yester|every)(?:day))'
re2=r'\d?\w*(ago|after|before|now)'
re3=r'((\d{1,2}(st|nd|rd|th)\s?)?(%s\s?)(\d{1,2})?)' % months
re4=r'\d{1,2}\s?[a|p]m'
re5=r'(\d{1,2}(:\d{2})?\s?((hour|minute|second|hr|min|sec)(?:s)?))'
re6=r'(\d{1,2}/\d{1,2}/\d{4})|(\d{4}/\d{1,2}/\d{1,2})'
re7=r'(([0-1]?[0-9]|2[0-3]):[0-5][0-9])'
re8=r'\d{4}'
relist= [re1, re2, re3, re4, re5, re6, re7, re8]
print("\n\nTemporal expressions are listed below:\n")
for exp in relist:
match = re.findall(exp,text)
for x in match:
print(x)
Output:
Enter the text:
I get up in the morning at 6 am. I have been playing cricket since 2004. My birth date is 1997/9/8. It has been 2 hours since I am studying. The time right now is 12:45. He is coming today. I study till midnight everyday. It takes 2 mins to solve this problem. He is coming in January. He went abroad on 2nd March, 1999. He was working here 5 years ago.
Temporal expressions are listed below:
('morning', 'mor', '', '')
('today', '', '', '')
('midnight', '', 'mid', '')
('everyday', '', '', 'every')
now
ago
('January', '', '', 'January', 'January', '', '')
('2nd March', '2nd ', 'nd', 'March', 'March', '', '')
6 am
('2 hours', '', 'hours', 'hour')
('2 mins', '', 'mins', 'min')
('', '1997/9/8')
('12:45', '12')
2004
1997
1999#Method 2Code:import reprint('Enter the text:')
text = input()
text=list(text.split("."))
months='(Jan(?:uary)?|Feb(?:ruary)?|Mar(?:ch)?|Apr(?:il)?|May|Jun(?:e)?|Jul(?:y)?|Aug(?:ust)?|Sep(?:tember)?|Oct(?:ober)?|(Nov|Dec)(?:ember)?)'
re1=r'\w?((mor|eve)(?:ning)|after(?:noon)?|(mid)?night|today|tomorrow|(yester|every)(?:day))'
re2=r'\d?\w*(ago|after|before|now)'
re3=r'((\d{1,2}(st|nd|rd|th)\s?)?(%s\s?)(\d{1,2})?)' % months
re4=r'\d{1,2}\s?[a|p]m'
re5=r'(\d{1,2}(:\d{2})?\s?((hour|minute|second|hr|min|sec)(?:s)?))'
re6=r'(\d{1,2}/\d{1,2}/\d{4})|(\d{4}/\d{1,2}/\d{1,2})'
re7=r'(([0-1]?[0-9]|2[0-3]):[0-5][0-9])'
re8=r'\d{4}'
relist= [re1, re2, re3, re4, re5, re6, re7, re8]
re_compiled = re.compile("(%s|%s|%s|%s|%s|%s|%s|%s)" % (re1, re2, re3, re4, re5, re6, re7, re8))
print("\n\n Output(with temporal expression enclosed within square bracket:\n")
for s in text:
print (re.sub(re_compiled, r'[\1]', s))Output:Enter the text: I get up in the morning at 6 am. I have been playing cricket since 2004. My birth date is 1997/9/8. It has been 2 hours since I am studying. The time right now is 12:45. He is coming today. I study till midnight everyday. It takes 2 mins to solve this problem. He is coming in January. He went abroad on 2nd March, 1999. He was working here 5 years ago. Output(with temporal expression enclosed within square bracket: I get up in the [morning] at [6 am] I have been playing cricket since [2004] My birth date is [1997/9/8] It has been [2 hours] since I am studying The time right [now] is [12:45] He is coming [today] I study till [midnight] [everyday] It takes [2 mins] to solve this problem He is coming in [January] He went abroad on [2nd March], [1999] He was working here 5 years [ago]
Sunday, September 13, 2020
Thursday, September 3, 2020
Tuesday, August 25, 2020
Monday, August 24, 2020
Saturday, August 22, 2020
Wednesday, August 19, 2020
Sunday, August 16, 2020
Various features of Markdown in Jupyter Notebook

Output of Emphasis:



Output of List:



Output of Links:

Output of Images:


Output of table:


Output of Blockquotes:


Output of Horizontal Rule:


Output of Youtube links:


Output of Headers:

Get the Github link here.
Web scrapping using a single line of code in python
We will scrap the data of wikipedia using a single line of code in python. No extra libraries are required. Only Pandas can do the job.
Step 1: Install and import pandas library
import numpy as np
Step 2: Read the data of web (here Wikipedia website) using pd.read_html('Website link here')[integer]
df = pd.read_html('https://en.wikipedia.org/wiki/COVID-19_pandemic_by_country_and_territory')[1]
Step 3: View the data scrapped from the web

Step 4: In case there are multiple table within a web page, you can change the index value to an integer starting from 0 until you get your required data (i.e. [0] or [1] or [2] or [3] and so on).
Build a colorful Word Cloud in python using mask image
Word cloud is a data visualization tool in data science. It is very efficient to visualize various words in a text according to the quantum of their repetition within the text. The stopwords have been ignored while visualization. A text file called "skill.txt" has been used to visualize. Mask image of map of Nepal has been used to visualize the word cloud.
The libraries required are:


Reading the text file "alice.txt" whose word cloud will be formed. After reading text file, setting the stopwords.

Generating a word cloud and storing it into "skillwc" variable.

Importing libraries and creating a simple image of word cloud (without using mask image).


Now, using mask image of map of Nepal to create word cloud. First of all, we will open the image and save it in a variable "mask_image" and then view the mask image without superimposing the text onto it.



Click here to download the collection of mask image.
Finally, we will impose the text file 'alice.txt' onto the image shown above with adding original color of image to the word cloud instead of default color.





