Kathmandu, Nepal

Please Subscribe

Built in OpenGL

Choropleth map

With masked image
Follow the given steps in order to solve the problem:
1. Use MongoDB compass for ease.
2. Open the "collection" in which you are facing a problem.
3. Delete all the indexes that were showing errors through MongoDB compass.
4. This should solve your problem.
If the error persists then either delete the collection whose attributes were showing errors or delete an entire "collections" of that particular database and create new ones.
You can also follow the steps shown in the video below:

Let us consider a sentence:
“This is going to be an amazing experience.”
Bigram for the above sentence can be written as:
With n-grams, we can use a bag of n-grams (for example, a bag of bigrams) instead of only using a bag of words. A bag of bigrams or trigrams is more powerful than using just a bag of words as it takes the context into consideration as well.
It is difficult to perform analysis on the text so we use word embedding techniques to convert the texts into numerical representation. This is also called vectorization of the words. It is a representation technique for text in which words having same meaning are given similar representation. It helps to extract features from the text.
i. Bag of Words (BoW)
It is one of the most widely used technique for word embedding. This method focuses on the frequency of the words. It is easy to implement and also efficient at the same time. In Python, we can use CountVectorizer() function from sklearn library to implement Bag of Words. A graphical representation of bag of Words has been shown in the figure below.
The reason for selecting BoW as word embedding technique is that it is still widely used technique due to its simplicity in implementation. It is also very useful when working on a domain specific dataset. If not entirely, it does give some idea to the researchers regarding the performance of the work.
Fig: Representation of BoW
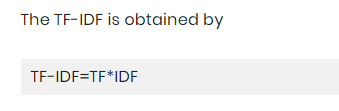
ii. TF-IDF (Term Frequency- Inverse Document Frequency)
Term Frequency is used to count the number of words in a document. It is not necessary that the words with higher frequencies tend to represent significant information about the document. A word appearing in a document for many times does not mean it is relevant and significant all the time. Many times, words with less frequencies carry more significant meanings about the document. One way to normalize the frequency of words is to use TF-IDF. Inverse Document Frequency (IDF) is used to calculate the significance of rare words or words with less frequencies.
The reason for using TF-IDF is it can be used to find and remove stop words in the textual data. It helps to find unique identifier in a text. It helps to understand the importance of a words in entire document which in turn can help in text summarization.
Confusion matrix is an important metric to evaluate the performance of classifier. The performance of a classifier depends on their capability predict the class correctly against new or unseen data. It is one of the easiest metrics for finding the correctness and accuracy of the model. The confusion matrix in itself is not a performance measure but all the performance metrics are based on confusion matrix. The ideal situation for any classification model would be when FP=0 and FN=0 but that’s not the case in real life. Depending upon the situation, we might want to minimize either FP or FN.
Fig 3.10 Confusion Matrix
Let us consider both the situations with the help of example.
Case 1: Minimizing FN
Let,
1 = person having cancer
0 = person not having cancer
In this case, having some False Positive (FP) cases might be okay because classifying a non-cancerous person as cancerous does not affect a lot because on further test we will anyway find out that the particular person does not have cancer. But having False Negative (FN) cases can be hazardous because classifying a cancerous person as non-cancerous can cause serious threat to the life of that person. So, in this case we need to minimize FN.
Case 2: Minimizing FP
Let,
1 = Email is a spam
0 = Email is not spam
In this situation, having False Positive (FP) cases i.e., wrongly classifying non-spam or important email as spam can cause serious damage to the business, financial loss to the individuals and so on. Thus, in this situation we need to minimize FP.
Various metrics based on confusion matrix
Accuracy: It is the number of correct predictions made by the model over all kinds of predictions made. It is a good measure when the target variable classes in the data are nearly balanced.
Accuracy = (TP+TN)/(TP+FP+TN+FN)
Precision: It is defined as the ratio of number of positive samples correctly classified as positive to the total number of samples classified as positive (either correctly or incorrectly). It reflects how reliable the model is in classifying the samples as positive. It is used if the problem is sensitive to classifying a sample as positive in general.
Precision = TP/(TP+FP)
Recall or sensitivity: It is defined as the ratio of number of positive samples correctly classified as positive to the total number of actual positive samples. It measures the model’s ability to detect positive samples. Higher the recall value, more positive samples are detected. It is independent of how the negative samples are classified. It is used if the goal is to detect all the positive samples without caring whether the negative samples would be misclassified as positive.
Recall = TP/(TP+FN)
LSA (Latent Semantic Analysis) is another technique used for topic modeling. The main concept behind topic modeling is that the meaning behind any document is based on some latent variables so we use various topic modeling techniques to unravel those hidden variables i.e., topics so that we can make sense of the given document. LSA is mostly suitable for large sets of documents. It converts the documents into a document term matrix before actually deriving topics from the documents.
Working of LSA:
The given text is converted into the document-term matrix using either bag of words or the Term Frequency- Inverse Document Frequency.
Then, using Truncated Singular Value Decomposition (SVD). It is at this stage the topics within the documents are identified. Mathematically, it can be given as,

Though it may look difficult to understand at first glance, in simple terms what the above formula represents is that it simply decomposes a high dimensional matrix into smaller matrices i.e., u, s, and v, where,
A = n*m document-term matrix (n = no. of documents and m = no. of words)
U = n*r document-topic matrix (n = no. of documents and r = no. of topics)
S = r*r matrix (r = no. of topics)
V = m*r word-topic matrix (m = no. of words and r = no. of topics)
Finally, we can now classify which document belongs to which topics.
Schematic diagram of LSA algorithm
Topic modeling is an unsupervised method used to perform text analysis. When we are given large sets of unlabeled documents, it is very difficult to get an insight into the discussions upon which the documents are based upon. Here comes the role of topic modeling. It helps to identify a number of hidden topics within a set of documents. Based on those identified topics, the entire sets of documents can be classified. Also, it can be used to predict the topic of upcoming documents. It can have various applications like customer reviews, story genre prediction, tweets classification, and so on.
LDA (Latent Dirichlet Allocation) is one of the most used and well-known techniques to perform topic modeling.
The word latent means hidden because we don’t know what topics a set of documents contain. Based on the probability distribution of the occurrence of words in each document, they are allocated to defined topics.
Working of LDA:
What we want for LDA is to learn the topic mix in each document and also learn the word mix in each document.
We choose a random number of topics for the given dataset.
Assign each word in each given document to one of the defined topics, randomly.
Now, we go through each and every word and to which topic those words are assigned in each document. Then, it is analyzed how often the topic occurs in the document and how often the word occurs in the topic as a whole. Based on this analysis, the new topic is assigned to the given word.
It goes through a number of such iterations and finally, the topic will start making sense. We can analyze those found topics and assign a suitable name to those topics which best describe them.
Fig: Schematic diagram of LDA algorithm
In traditional neural networks, inputs and outputs were independent of each other. To predict next word in a sentence, it is difficult for such model to give correct output, as previous words are required to be remembered to predict the next word. For example, to predict the ending of a movie, it depends on how much one has already watched the movie and what contexts have arrived to that point of time in the movie. In the same way, RNN remembers everything. It overcomes the shortcomings of traditional neural network with the help of hidden layers. Because of the quality to remember the previous inputs, it useful in prediction of time series. This is called Long Short-Term Memory (LSTM).
Fig: LSTM Architecture
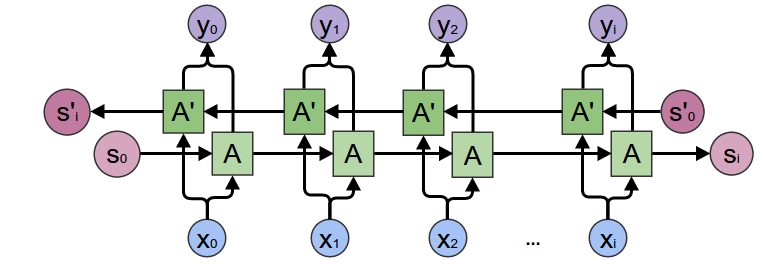
Combining two independent RNN together forms a Bi-LSTM (Bidirectional Long Short-Term Memory). It allows the network to have both forward and backward information. Bi-LSTM gives better result as it takes the context into consideration.
Example:
In NLP, to find the next word, it is not that we need only the previous word but also the upcoming word. As shown in the example above, to predict what comes after the word “Teddy”, we can’t be dependent only upon the previous word (which is “said” in this case) because it same in both the cases. Here, we need to consider the context as well. If we predict “Roosevelt” in the first case then it will be out of context as it will read as [He said, “Teddy Roosevelt are on sale!”]. So, Bi-LSTM is important to taken context into consideration.
Fig: Bi-LSTM Architecture
Topic modeling is an unsupervised technique as it is used to perform analysis on text data having no label attached to it. As the name suggests, it is used to discover a number of topics within the given sets of text like tweets, books, articles, and so on. Each topic consists of words where the order of the words does not matter. It performs automatic clustering of words that best describe a set of documents. It gives us insight into a number of issues or features users are talking about, as a group.
For example, let us say a company has launched the software in the market and receives a number of feedback regarding various product features within a specified time period. Now, rather than going through each review one by one, if we apply topic modeling, we will come to know how users have perceived the various features of the product very quickly. It is one of the essential techniques to perform text analysis on unstructured data. After performing topic modeling, we can even perform topic classification to predict under which topic the upcoming reviews fall. There are various techniques to perform topic modeling, among which LDA is considered to be the most effective one.

Lack of availability of enough domain-specific dataset
Multi-class classification of the data
Difficult to extract the context of the post made by the users
Handling of neutral posts
Analyzing the posts of multiple languages